本文摘自:逆流而上:阿里巴巴技术成长之路
背景
随着阿里巴巴集团业务的高速发展,数据中心的数量和规模都在快速扩张,网络运营的设备数量、型号、软件版本的类型均呈快速增长的趋势,网络规模的扩张导致了相同故障发生概率下出现设备转发异常的次数也在不断增加,对业务影响和网络运营带来了很多风险和挑战。
常见的网络丢包故障发生在线路和端口级别,大都是因为线路质量劣化、线路流量拥塞、光模块故障等,这类问题网络运营团队有成熟的监控和自动化处理手段,可以确保故障被快速发现、定位和恢复。
在各类转发异常中,最困扰网络运营的难题就是静默丢包。静默丢包是发生在设备内部转发层面的,没有任何异常日志或告警的丢包故障。由于没有任何迹象可寻,静默丢包的发现和定位都是一个难题。
随着网络规模不断增加,网络设备静默丢包虽然为小概率事件,但其故障数量呈上升趋势,较长的故障定位和恢复时间都是业务所不能容忍的,网络运营是时候向静默丢包正式宣战了!
异常表现
静默丢包主要有下述异常表现。
(1)特定流持续不通。
(2)持续网络重传。
(3)特定大小报文丢包。
(4)固定时间出现丢包异常。
原因分析
若对静默丢包的原因进行详细分类,可以归为以下两类。
第一类:软失效
Parity Error产生的原因是芯片软失效,Parity Error是芯片软失效的一种校验方法。软失效是指高能粒子单元对芯片晶圆的撞击导致比特翻转而引起单比特错误、多比特错误及栓锁等,由于它对电路的损害不是永久性的,所以这种现象被称为软失效。
产生软失效的原因有以下三种。
(1)芯片封装材料含有放射性元素引发芯片软失效。
(2)来自宇宙和太阳系的高能中子芯片的原子核捕获产生附属的带电粒子,进而引发芯片软失效(是的,经常被大家调侃时说的太阳黑子爆发导致数据中心异常是真实发生的)。
(3)低能中子会和芯片内部绝缘体材料发生原子反应,产生高能粒子,引发芯片软失效。
软失效易发生于半导体存储芯片中(如DRAM、SRAM、寄存器组),以及高速缓存和配置寄存器设备等。目前软失效无法完全避免,具有随机性和不确定性。软失效一般都是静默丢包问题的主要来源。
软失效又分SBE(Single-Bit Error,单比特错误)和MBE(Multi-Bit Error,多比特错误)两种情况,所谓单比特错误SBE,是指在一个数据字中因为芯片软失效引起的一个比特的错误,而多比特错误MBE是指在一个数据字中因为芯片软失效引起的两个或多个比特的错误。通常,发生多比特错误的概率较低,但一旦发生,就极难纠正错误比特。
为了降低软失效问题发生的概率,芯片和半导体厂商分别从工艺和系统两个方面着手改进。工艺级措施方面选用放射性元素含量极低的封装材料和采用新的绝缘体材料技术,系统级措施采用奇偶校验(Parity Protection)、纠错码(Error Correction Code,ECC)和双存储器的软硬件比较等技术来预防软失效的发生。
现有网络中各商用设备在关键转发表项上通过ECC字段来检测SBE和MBE,当发生校验错误时通过发出告警信息告知用户,同时硬件可以通过ECC字段信息自动纠错SBE,但无法纠正MBE,MBE则是通过上报中断,采用软复位(soft reset)、硬复位(hard reset)或软件重刷硬件表项。这些都依赖于芯片厂商的开发程度、检验和恢复机制,以及设备厂商的软件支持程度,如果芯片和SDK支持不足对一些非关键表项没有覆盖检测和自修复,又或者在芯片没有覆盖到的关键表项,设备厂家没有通过有效的软件机制解决都会导致网络设备出现静默丢包的问题。
第二类:设备硬件故障、软件缺陷和性能问题
设备单板芯片或外围器件硬件故障,软件本身机制考虑不全或实现有误等缺陷以及设备内部通道异常或拥塞都会导致业务出现丢包或异常篡改。对于设备硬件故障和软件缺陷之类的各个版本和厂家的问题具有多样性且无通用性,这里就不展开了。
故障发现
现有的静默丢包网络监控手段有传统手段(SNMP(简单网络管理协议)集采和实时系统日志分析)、主动测试发现手段(各种大小报文并且变换源目的TCP端口的TCP fullmesh(全网状)ping)和人为可定义的巡检系统,但是受限于监控周期、巡检和flow覆盖能力以及安全要求,仍然会有一些特定五元组报文不通或间歇性丢包重传等静默丢包问题需要依靠业务上报。
故障定位和处理
由于业务提供访问异常流量的源目的在转发路径上会经过很多网络设备,在问题定位过程中需要在所有的网络设备端口上去部署流,然后根据比较计数来定位丢包点,这就要求对流统flow(特定五元组的流量)灵活的打标和染色能力进行计数比较来确定问题。
这里分别从特定流不通和随机丢包两种情况来说明传统的定位方法和步骤。
第一类:特定流不通
这种问题属于静默丢包类最常见的问题,业务抓包可以发现特定五元组的包数据持续永久不通,对于这种转发路径上报文计数从有到无的异常,相对来说定位条件和难度较低。假设现在发现源端口1234、目的IP和端口为1.1.1.1:80的syn包不通而源端口为1235时是通的,则可以使用命令:sudo traceroute -Tp 80 –sport=1234 1.1.1.1 和sudo traceroute -Tp 80 –sport=1235 1.1.1.1,这就相当于分别用异常流和正常流去做traceroute比较看断点在哪里,在断点的上下游设备上分别做流通,这种方式也受限于服务器本身traceroute的版本和设备的ttl超时答复功能开启等,通用的方法是服务器构造持续发送不通的特定流,路径上做流统抓取从有到无的故障点。
第二类:随机丢包
这种问题对传统定位具有很大的挑战性,不是有和无的区别,而是多和少。正如前面描述的流统局限性,先要搭建一个和业务流相近的环境,然后在所有转发途径的设备端口部署流统,这需要大量的人力资源和时间成本。
综上所述,流统是一个原理简单、定位准确的静默丢包定位手段,但是其最大的弊端是策略部署和报文统计环节的工作太重,需要在业务流所途径的所有ECMP(Equal-CostMultipatchRoutig,等价路由)路径去部署策略并统计结果,人工实施一次流统大概耗时几个小时,如果一天要排查多个静默丢包的问题,其工作量可想而知。
由于这类问题的定位思路和方法是可以固化的,而且传统方式依赖于个人对设备命令的熟悉程度,并要自己去分析转发路径。因此,网络人员将固化的经验沉淀到系统中,以实现智能流统的自动化运营手段来提升整体工作效率。下面将详细描述静默丢包智能流统工具的实现和定位思路。
(1)寻找丢包五元组
由于业务人员的水平参差不齐,无法准确给出丢包的五元组,这就需要借助智能化流统工具来定位发生丢包的五元组。输入用户提供的源目的IP后,系统会以源端自动构造报文(源目的端口不断变化)发送到目的端,目的端进行报文分析并返回结果,如图1-1所示。
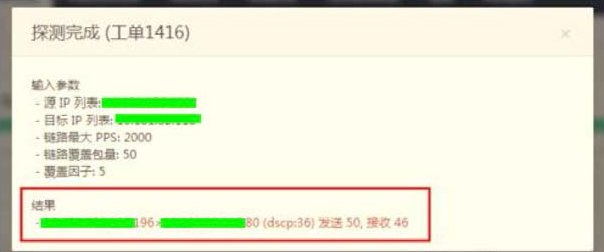
图 1-1 定位丢包五元组的结果
(2)自动发现网络拓扑、下发流统策略并发起测试
如图1-2所示,系统会根据输入的AB端服务器信息,自动发现途经的端到端网络拓扑,生成源到目的的转发路径,并下发流统策略,完成流量策略部署后,系统会通过安装在服务器上的AGENT,从服务器发起针对特定流的发包测试。
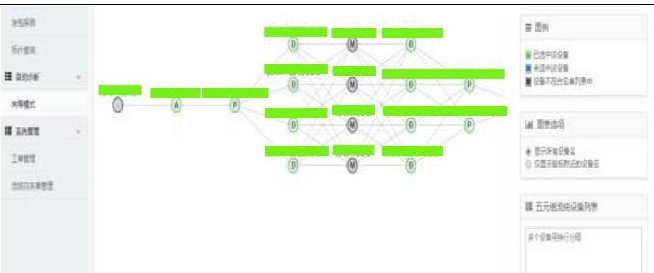
(3)流统结果采集和诊断结果的展示
这个步骤是将所有设备上的流统计数进行采集分析并图形化展示丢包位置,该步骤代替了人脑分析的过程,自动反馈有问题的故障点并标红,这个时候整个定位过程就算完成了。
此时我们可以看到集群出口交换机的一条链路in流量已经减少了,证明流量在POD出口交换机→集群出口交换机转发时发生了丢包,如图1-3所示。
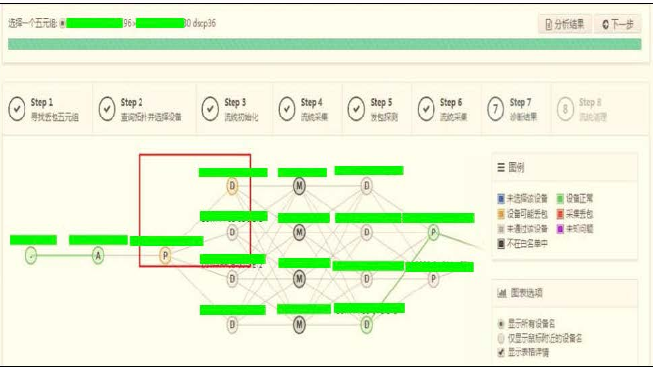
图 1-3 故障定位段落展示
在明确故障点之后,通常是优先恢复业务,由于网络设计上的冗余性,可以直接隔离异常芯片或板卡。通过隔离处理后发现业务恢复正常。
小结
通过智能流统的实现,逐渐将人从重复及固化的操作中解放出来。从人力上讲,传统方式需要多个跨团队的人员协作,演变成个人单兵作战完成问题定位;从时间上讲,由几小时简化到几分钟,大大降低了故障影响并缩短了定位时间。
未来,智能流统工具前向会和业务告警、网络监控系统结合,在业务异常时,自动启动并快速定位故障段落;后向会和网络自动化运维平台打通,在定位问题后触发自动化隔离,实现故障的自动发现、定位和解决,真正做到自动化运维。
随着更多的自动化运维工具的上线,也使网络运维自动化越来越迅捷和高效,网络运营已经进入了自动化、智能化的新阶段。