本期 ISSCC 论文解读有幸邀请到中科院半导体所的祁楠教授。 祁楠师兄博士毕业于清华大学微电子所,并随后在美国的高校、企业实验室工作,主要研究光通信电路和硅光电集成芯片,学术界和工业界的经验都非常丰富。 目前他的课题组跨光、电两个领域,主要围绕 CMOS 硅基光电集成、高速通信电路等芯片开展研究 ,并在包括固态电路领域的 CICC 、 RFIC 、 ASSCC 、 JSSC 和光通信领域 OFC 、 JSTQE 等会议、期刊中发表多篇论文。 这次祁楠师兄不仅在百忙之中抽出时间做了论文解读,还 对硅光的应用背景、研究难点、发展趋势做了大量延申讨论。 六千字的雄文,干货满满,不管是对硅光有兴趣,还是正在从事这方面的研究,都值得静下心来好好阅读多遍。闲话少说,我们来看正文。
(此文有6219字)
▼
各位朋友大家好,本人学生时代做过模拟和射频电路,毕业后接触到光通信电路,并恰赶上硅基光电子( Silicon Photonics )迅速发展的快车。 借最近宅在家里的难得机会,通过贾教授的平台和大家进行交流。 目的很简单,让做电路的朋友了解光通信这个快速发展的方向,并向做光的朋友“推销”光电集成将带来的巨大机遇。 我们课题组期待与志同道合的业界朋友进行合作,并欢迎感兴趣的同学们积极报考和加入。 另外,我在科学院大学的秋季本科《非线性电路》和春季研究生《光电集成芯片中的高速电路设计》的课程都会讲授该方面内容。本期与大家分享的论文来自 Intel ,作者也是笔者的朋友(敬称“昊总”),本篇论文是典型的硅光子与电路集成之作,也是作者及其公司长期积累的方向。
1、应用背景数据中心的互连带宽需求飞速增长,虽然目前产品主流是 100G ( 4x25G )光模块,但国际范围都紧盯着 400G 开展研究,其中单波长速率期望达到 100Gb/s 。 这里需要说明的是,光通信系统中还有另一维度波长(类似于无线通信载波频率),由于长距离通信常采取波分复用同一物理信道,人们通常用 “ 单波长 ” 来对应电芯片中的单通道。 考虑到本文主要讲电路,我们暂且简单称之为 “ 单通道速率 ” 吧。单路速度的提升引入越来越大的功耗、串扰和散热方面问题 。 我们看下图,传统的 plugable 光模块一般都放在服务器背板边沿,服务器 Payload 主芯片( xPU 、 switch 、 FPGA 等)需要先走一长段背板线才能到达。 在单路 100Gb/s 速率下通常需要 n 多 tap 的 FFE 、 DFE 电路均衡走线的高频损耗。 大家不难想象,仅仅是把数据走到光口,可能上百 mW 功耗就已烧掉,更别说多路并行的总能耗和串扰了。 另外,密密麻麻一排光模块堵在板边沿,服务器内风路不畅,散热也成了大问题。

如果把每个光模块做小,并围绕服务器主芯片就近放置,上述长走线问题就有望大幅缓解 。 这是目前国际范围的发展趋势 —— 共封装( co-packaged )板载光模块( On-board optics ),我们形象的称之为 “ 芯片出光 ” 。 Intel 擅长做 chiplet (详见 session-8 ),几个裸片封到一起,再罩个盖子,外表看就像一个直接以光信号通信的 magic chip 。 如下图所示,这种情况下光模块端的电路也可简化: 节省掉(或使用轻度的)均衡与时钟数据恢复( CDR ),并降低接收端灵敏度需求。 当然,此发展趋势还要平衡旧有商业利益的问题,其大规模产业化还有待观望。
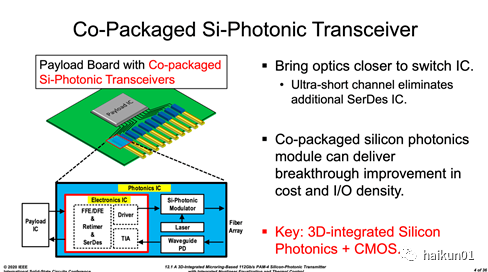
2、光电协同设计光模块小型化最大的挑战是提高芯片集成度和降低功耗,而硅基光电子( Silicon Photonics )在 CMOS 兼容的衬底上同时制备光器件和高速电路,是实现此目标的有潜力方案。 说句题外话,我们这里强调 “CMOS 兼容 ” ,是因为至今硅光技术还未实质的将光电单片集成推进到实用化。 一方面光器件大部分性能仍被 III-V 族完爆; 另一方面,也是最重要的,光器件尺寸与深亚微米 CMOS 晶体管不在同一量级,目前主流应用场景中单片化成本上不划算。本文选择了微米量级的硅光微环谐振型调制器( Micro-ring Resonator Modulator, MRM )作为上述问题的突破口,原因有三: 首先尺寸小, 相比于马赫 – 赞得调制器( Mach-ZehnderModulator, MZM )动辄 2-3mm 的长度,它的尺寸下降两个量级,直径大概只有 20um 左右,为将来光电单片化打开大门; 其次好驱动 ,相比于 MZM 等效 50-ohm 的阻抗, MRM 仅相当于 PAD 大小的一个电容负载,使得 CMOS 反相器直接驱动成为可能; 再次并行度好 ,多个 MRM 并行集成,可实现天然的波分服用( WDM ),无需额外的透镜芯片。简单科普一下 MRM 的原理,光波信号在芯片上的 “ 导线 ” 称为波导,在硅光工艺中就是用 SiO 2 包裹着纯 Si 做一个 “ 管道 ” : 光在里面透射不出去,只能直线或者来回反射着向前传播。 我们在波导总线旁边很近的地方(几微米,但不接触),放置额外的闭合环形波导,总线上的光能量将泄漏到环中,使得总线最终输出能量减小。 这里一个有意思的特性是,当某波长的光沿微环走一圈恰是其波长的整数倍时,大部分能量都将困到环中,不再沿总线传输了。 而如果人为改变加在环形波导中的电场,光波的传播速度会改变,那么它走一圈的时间会改变,即环形波导的谐振波长将改变。 利用这一特性, MRM 就类似于一个高 Q 值的“坑状”带陷( notch )滤波器,滤除掉极小波长范围的光。 而对于固定波长的信号,我们在 MRM 波导上施加交变电压,就能造成其谐振波长往复平移,进而产生对总线光信号强度的调制效果。 再进一步,如果我们沿总线放置多个微环,并且设置它们具有不同直径,就能得到多个分离谐振波长,这就使得单信道的波分复用成为可能。 当然,在一定范围内容纳更多波长,实现密集波分复用( DWDM ),带陷滤波的 “ 坑 ” 就必须足够窄和深。
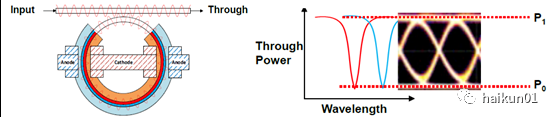
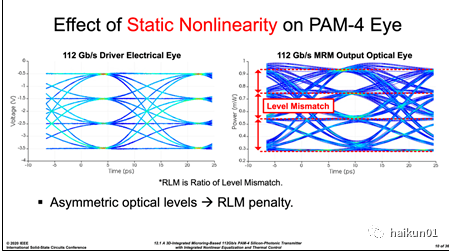
在 PAM4 调制下, MRM 调制器最关键的三项参数,也是其驱动电路最大的设计挑战,是调制效率、线性度和波长稳定度。 下面我们力求形象的逐个进行说明,(1)调制效率为了调制后的 ‘0’ 和 ‘1’ 有足够区分度(称为消光比 ER ) ,我们希望 MRM 的波长选择对带内 / 带外信号抑制度足够大。 由于调制是靠平移微环的谐振波长实现的,上述语句就翻译成 调制产生的谐振波长移动足够大 。 为此,我们要么做一个高效率 MRM ,在低电压幅度驱动下就能实现足够大的波长移动; 要么做一个电压摆幅高的驱动芯片,造成光波传输速度的改变非常大。本文中 Intel 做的 MRM 显然比较牛,详见他们 2018 年 OFC 的论文 [1] ,其结果是仅需要差分 2.4Vpp 的驱动电压,就可产生 >5dB 消光比,还能有 50GHz 的调制带宽。 这和文章作者 2015 年 ISSCC 文章中的 MRM 相比,所需幅度降低近一半,带宽反而提升近一倍。 本文则关注于电路技术,旨在实现大摆幅的驱动电压。 具体来说,就是要用单管耐压 0.9V 的 28nm CMOS 电路,实现高速 3Vpp 的输出摆幅。(2)线性度首先, MRM 存在静态非线性 ,如下图即便 driver 输出理想线性 PAM4 波形,电光转换后也将产生明显的非线性 “ 大小眼 ” ;
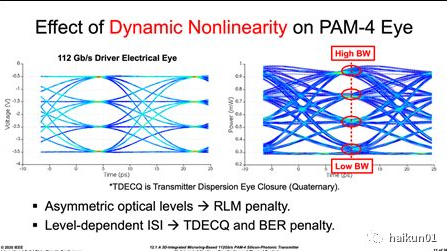
其次,耗尽型 MRM 存在动态非线性 ,驱动电压大范围变化导致其等效电容受调制,造成驱动信号在逻辑高和低处带宽不相等。 仔细观察下图,带宽不足的程度还与码型相关: 短 “0” 的带宽不足最明显,因此均衡时需要针对码型提供不同的均衡强度。 本文的主要贡献在于此处,即提出了非线性预失真( NL-PD )和非线性 FFE ( NL-FFE )相结合的均衡方法,抵消上述两种非线性。
(3)波长稳定性MRM 到目前为止最大的技术难题是其波长的稳定和调节。 前文我们提到,为提高输出光信号消光比、支持 DWDM , MRM 的滤波特性陷波 Notch 必须非常窄, Q 值高达上千。 在此情况下,工艺偏差、温度变化都将造成显著的谐振波长漂移,必须搭建光电闭环的调节系统再出现 PVT 偏差时将波长稳定在确定数值。 本文的主要贡献也在于,提出改进型的波长自动稳定技术,监控并实时调节 MRM 波长。3、电路和系统亮点本文内容较多,全部平叙一遍可能导致读者丢掉重点; 因此,我们仅对应上面提到的三项参数,向大家分别解读亮点工作,而剩余细节电路则留给感兴趣者深入研读。(1)高速大摆幅输出级为实现足够大的消光比,我们需要在高速下提供 3Vpp 的输出摆幅。 如下图,本文 Driver 由 30 个结构相同和尺寸不同的单元并联实现: 每个单元内,差分信号到达输出级之前分成工作在 0~VDD 和 VDD~2*VDD 的两条并行之路: 前者在输出逻辑高时,负责将负载电容上拉到 2*VDD ( 2.2V ); 后者则负责在逻辑低时,将负载电容泄放至 0 。 这相当于把 2.2V 电压摆幅均摊到两个串联的 PMOS (或 NMOS ),实现了 2 倍于单电压域的电压摆幅。 与此同时,类似于 SST 型电压 driver ,每个 driver 单元的输出阻抗由晶体管导通电阻、额外串联的电阻 R L 构成,用来吸收封装后信道不连续导致的反射。 文中作者声称额外的 R T 用来提升线性度,笔者猜测 driver 输出阻抗随 PAM4 调制变化较大,因此额外并联固定数值 R T 可缓解其波动,其代价可能是充放电速度和输出摆幅的降低。 SST driver 的阻抗控制这里不再展开,感兴趣的朋友借鉴一下相关 SERDES 论文。
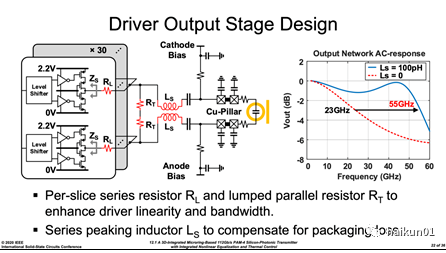
考虑到 driver 与硅光 MRM 的对接, 首先,调制器 PN 结(也就是差分两端)之间需要一个反向偏置 ,因此 driver 和 MRM 通过电容耦合,阴极和阳极分别通过电阻外加偏压; 其次, MRM 的容性负载导致 driver 输出带宽不足 ,本论文通过 series-peaking 电感的方式,将核心电路和负载大电容隔离,获得 32GHz 左右的带宽提升。
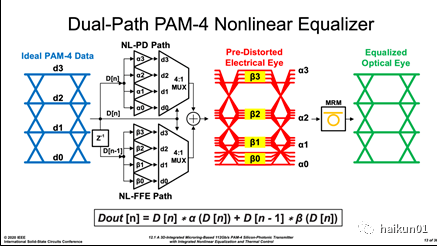
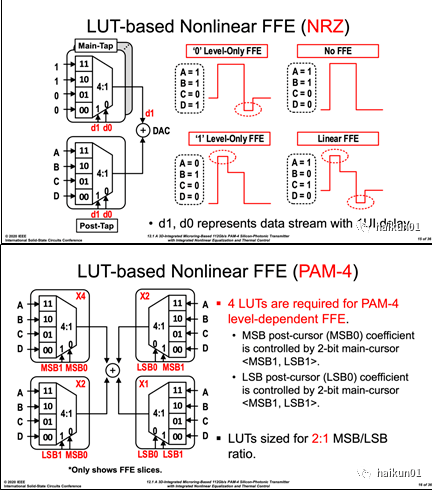
(2)非线性驱动与均衡这部分比较复杂,我们看 最终目标: 为抵消 MRM 两种非线性, driver 需要将理想 PAM4 波形(蓝色),预失真成特定形状(红色),以获得线性度改善后的光眼图(绿色)。 从上向下观察目标眼图形状,其眼高依次变化(预失真比例系数 αn ),均衡的强度也各不相同(预失真比例系数 βn ); PAM4 每个眼皮处都呈现四种不同预加重强度,并取决于前一 UI 的数据码型。 这里笔者认为红色曲线的绘制,在均衡强度逻辑上稍有点错乱,有待读者根据自己理解进行判断。为达到上述效果,作者把 driver 主要电路做成结构相同、尺寸各不相同的 30 个 slice ,其中 21 个一倍尺寸( 1x )单元给线性双抽头( 2-tap ) PAM4 调制,( 4*1x+1*0.5x )单元给非线性预失真,( 1*1x+2*0.5x+1*0.25x )给非线性均衡。 这里要注意的是,每个 slice 中是 28Gb/s NRZ 的 CMOS 信号,只有在最终相加节点才产生 56GBaud/sPAM4 信号; 每个 slice 中都有独立的查找表( LUT )、串化器( 2 : 1 )和 SSTdriver 。
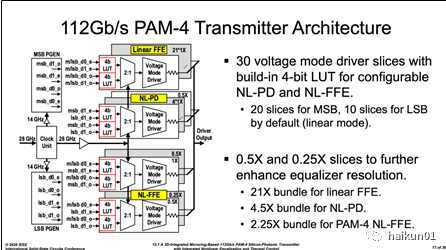
为了在对应不同数据电平( A/B/C/D )的情况下,打开对应数目的 driver cell 单元,本文将上述 30 个 slice 按照温度计码方式进行排列组合。 这里有点绕,我们先看非线性预失真的编码方法: 线性情况下显然为等间隔为 8 的四个幅值( 24/16/8/0 ); 而为了抵消非线性 “ 大小眼 ” ,上述码型预失真为( 24/13/5/0 )。 具体电路实现中,则使用 PAM4 的 2-bit 输入信号( MSB/LSB ),直接选中四个电平所对应的温度计编码( 24/13/5/0 )进行输出。 每位数据的 LUT 具体电路如下图所示,其核心思路是最小化对输出节点充放电时间,减少关键路径上串联的晶体管个数,因为 DUT 都运行在 28Gb/s 。
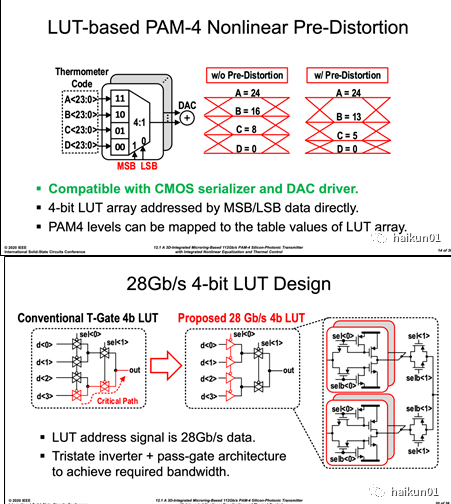
上述思路同样可使用在 FFE 中,比如在 NRZ 调制时可根据数据流的相邻 2 个 UI 数据 d1 、 d0 ,去选择当前码型转换时 main-tap 和 post-tap 分别打开的 slice 的数量,实现与码型相关的均衡。 扩展到 PAM4 调制情况,则应当产生( 1*1x+2*0.5x+1*0.25x )四种 slice 的打开与否的控制信号,这在下图中分别对应了 x4 、 x2 和 x1 的四个 LUT 。 具体的编码对应关系我们不再细讲,但需要注意的是,这里的求和 DAC 指的是最终 driver 输出节点,而并不是在 DUT 的输出就进行了求和处理,因为在输出级之前信号通路上传输的仍是 NRZ 格式。
(3)波长自动调节MRM 的谐振波长对温度变化非常敏感,文中提到约为 10GHz/K ; 考虑到谐振时 Q 值非常高,闭环实时调节是稳定工作所必须的。 常用的波长调节方法是从 MRM 波导总线分出 5-10% 的光功率,反馈到一个集成在调制器上的监控探测器( monitoring PD ); 该功率转换成电流作为监控对象。 波长调节则试图使此平均光功率达到最大值,以实现输入信号波长对准到调制器自谐振波长。 微环的波长控制常采用加热波导的方式,即在环形波导附近放置电阻并施加电流,利用 DAC 调节此电流而控制实时加热功率,将 MRM 谐振波长稳定在期望值附近。 上述过程中,几个关键参数需要考虑: 调节精度、调节范围、硬件代价、能耗效率和反馈调节的可信度。
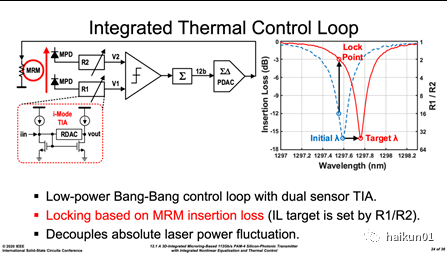
传统的波长闭环监控,采用低带宽的光电转换和放大器件,仅观测平均光功率的绝对值进行调节。 它的问题在于观测值的变化可能来自入射光功率、信号码型、 MRM 滤波等多个因素,据此调节的结果可信度可能较低。 本文对此进行改进,同时将进入和通过 MRM 的平均光功率拾取出来,监测其相对数值变化,更大的差值意味着更多的功率 trap 在微环中,即谐振波长更接近输入信号波长。 另外,观测量转化成两路径输入 I-V 增益的比 R1/R2 ,避免了与绝对数值(片上很难实现)相比,提高了反馈调节的置信度。 这里笔者有个小疑问,两次 MPD 的光功率拾取,必然造成更大的光功率分流,这就对整个 TX 光路损耗提出更高的要求,不知道本文实际的链路开销如何。另外,为了同时实现大调节范围和精细调节步长,我们需要较大的反馈系统线性动态范围,本文是通过两部动作实现: 首先,使用 sigma-delta 调制器的方式实现 12-bit 的电流 DAC ; 其次,将光功率通过 MOS 管平方率特性向电流量纲做线性映射。 两者结合实现 50mW 功率范围, 14uW 的调节步长。
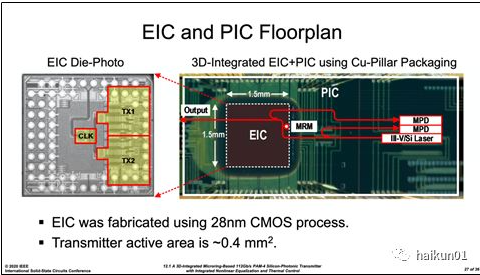
4、测试结果讨论首先,我们来看看本文实现的完整光电集成发射机系统。 得益于 Intel 强大的集成能力,本文的电芯片 EIC 倒扣在一个大的硅光芯片 PIC 上,并通过 Cupper Pillar 进行电气连接; 同时 III-V 族激光器通过混合异质集成的方式,生长在同一个硅光芯片上; 上述作为承载体的硅光芯片在通过平面金线的方式,集成到一个 PCB 基板上。 这种集成方案的优势是:( 1 )高速信号仅通过 cupper pillar 出现在 EIC 和 PIC 两芯片间,电源和低速信号通过 PIC 连接至 PCB ,在 112Gb/s 速率信号完整性好;( 2 )激光器直接出光至片上波导,与外置激光器方案相比节省了输入光纤耦合的次数,有望提高整体光链路的信号插入损耗裕量。 上述两芯片构成一个(目测)仅有数平方毫米的小型化共封装光电引擎,适用于本文开头提到的板载光模块。
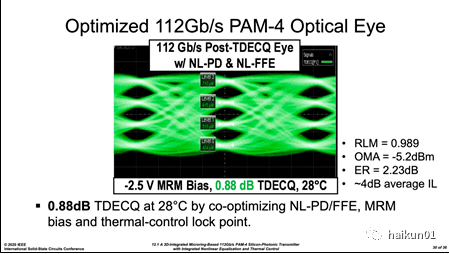
文中两种均衡的效果在上图中得到验证,通过 NL-PD 有效改善了 “ 大小眼 ” 问题; 与之相比在 -0.7V 下 NL-FFE 的均衡效果似乎没那么明显,这主要是因为反向偏置太低, MRM 器件结电容导致带宽不足,而提高 FFE 强度带来逻辑低时 overshoot 比较明显。
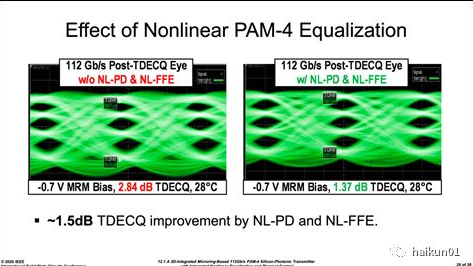
为了得到更好看一些的眼图,作者提高了反向偏置,并且优化了均衡和波长调节; 笔者这里认为提高偏置的影响可能是主要的,估计也相应降低了 FFE 强度。 这样一来眼图质量得到明显提升。 关于 TDECQ 是什么意思呢? 笔者在这里仅简单的介绍一下,想象我们的 TX 芯片发射 PAM4 光信号,与此同时还有一个理想的 TX 也发射相同的 PAM4 信号,假如用相同的光电接收机去处理并实现相同的 BER 目标,显然我们的芯片需要该接收机 “ 费更大的劲 ” ,这转换成 dB 量纲就是上述的 TDECQ ; 而实际情况下,测试仪器是通过叠加不断增大的噪声来寻找上述数值的。 显然 TDECQ 越小,说明我们的 TX 越接近于一个理想的 golden TX ,性能也就越好。
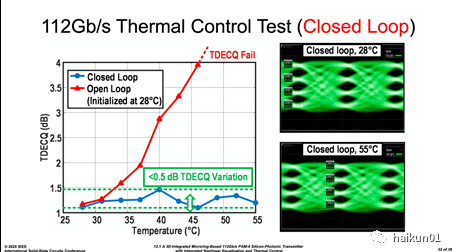
最后,我们来看看波长调节带来的效果: 实测在 28°C 到 55°C 下都能保证 TDECQ 不会恶化 0.5dB 以上,这是一个很有效且直观的数据支撑; 而开环情况下, 40°C 左右基本信号质量就差到不可用了。 波长自动调节是微环谐振型光电收发机,走出实验室实现未来量产化,最重要的技术。 当然,波长稳定目前还有许多未解决的问题,例如大芯片中的热串扰、调节范围、响应速度、 DWDM 多波长情况下的调节逻辑等,这些也都是读者可以深入探索的潜在方向。
4、总结面对数据中心,尤其是 Switch 等应用中对于高密度、低功耗、高带宽光模块的需求,光电接口仍是整个链路的性能瓶颈; 微环 MRM 收发机的光器件尺寸小、驱动能耗低,恰能解决上述问题。 MRM 光器件本身呈电容性负载,便于深亚微米 CMOS 工艺下与数字电路的集成,是最有可能实现光电单片集成的方案之一。 然而长期以来,国内惯性思维认为该方案波长稳定问题难以跨越,距离实用化遥遥无期,也不愿投入过多精力开展研究; 而已开展的研究多集中于单独微环光器件的优化,与电路集成方面涉猎较少。笔者在这里认为,在当前技术发展的趋势看,我们应跳出传统光电分家的视角来看待此问题。 硅光子技术最大的特点是与 CMOS 电路的兼容,我们应充分放大此优势,借助大规模 CMOS 电路强大的处理能力解决上述问题。 以近期关注度较高的创业公司 Ayar Labs 为例,通过单片光电集成,数据传输的能耗效率已降低到标杆性的 1pJ/bit 以下,而单片总带宽也达到 1.2T 水平,实现了上述技术的初步产业化。 笔者相信微米级的硅基光电集成,为后摩尔时代集成电路的发展,探索出一条崭新的、前景可期的道路。 最后,如果大家问我 Ayar Labs 做的究竟怎么样? 我借用“昊总”先前私下的交流: “非常牛”。感谢大家阅读本期对于 ISSCC2012-1 论文的解读,接下来我们会继续和大家分享更多的光电集成方向的优秀论文。 祝大家早日发上ISSCC。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。