【导读】wayve是英国一家致力于通过强化学习实现自动驾驶的初创公司,本系列通过该公司已发布的论文和博客来解析Wayve的技术。

Wayve由两个剑桥大学机器学习博士生Amar Shah(任CEO)和Alex Kendall(任CTO)在2017年创立。与其它公司的激光雷达路线不同,Wayve只使用单目摄像头作为传感器设备来尝试实现自动驾驶,是一家使用强化学习作为主要技术的初创公司。从他们公布的视频来看,不到两年间他们的测试车辆已经取得了很好的路测效果。

本文分为下面两部分内容,有一些论文中未详细说明的细节笔者也与Wayve进行了确认。
- 一天内学会驾驶(Learning to drive in a day)
该任务其实比较简单,即在一条车辆稀少的乡间道路保持车道线跟踪。但这项工作的吸引人的地方在于实现该任务只用了15~20分钟。模型输入单目摄像头的视觉图像,输出是车辆的转角和速度命令,选用的强化学习算法是Deep Deterministic Policy Gradient (DDPG)。
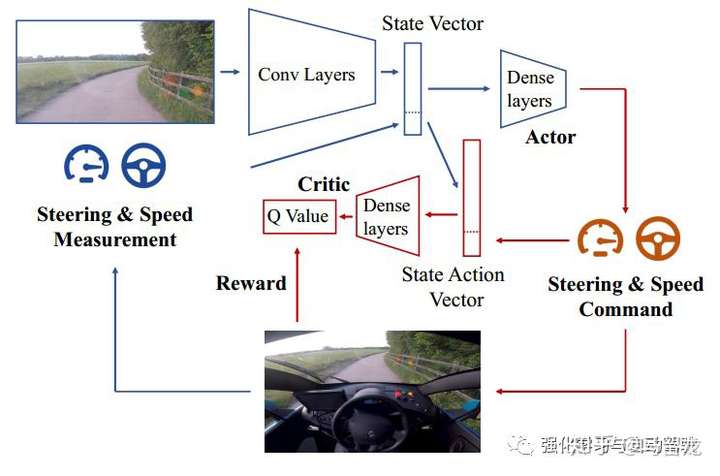
DDPG一种actor-critic算法,其中actor进行决策,critic负责评估,学习的目的是使actor决策得越来越好,critic评估得越来越准确。模型的输入即state是实时获取的单目图像与当前测量的车辆转角和速率,图像经过卷积神经网络提取特征后与两个测量量共同输入全连接神经网络来决策运动命令。Critic输出evaluated Q value,而target Q可以根据Reward计算得到。Reward在该任务中设计得很简单,为当前状态下车辆平均可自动驾驶的距离。在该任务中,他们还专门通过Unreal Engine 4设计了一个三维驾驶仿真器来寻找更优的网络结构和超参数。为了提高采样效率,与我们之前的工作相同,他们也使用了变分自编码器(Variational Autoencoder, VAE)来压缩图片,不同之处是在这该网络中使用了更浅的深度与隐向量数使得网络的参数大大减少。VAE的网络结构如下所示:
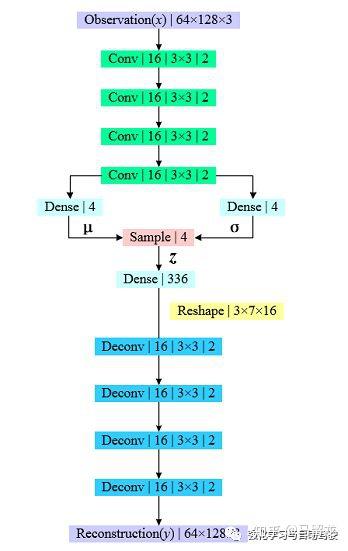
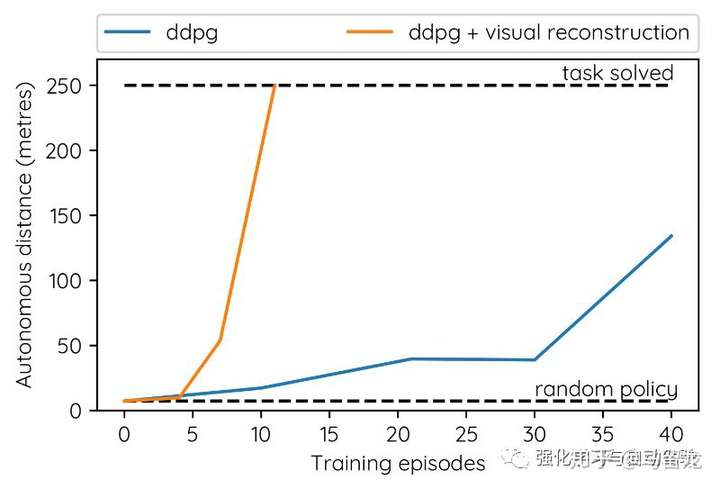
Alex Kendall在回复我的邮件中,说他们一般使用的隐向量个数是2~32,在这个任务中选用的4。在训练VAE时只在仿真器中收集了5个episodes的数据,在真实环境中VAE的encoder和策略网络耦合训练。VAE的使用极大提高了学习效率:
整个模型的网络结构如下所示:
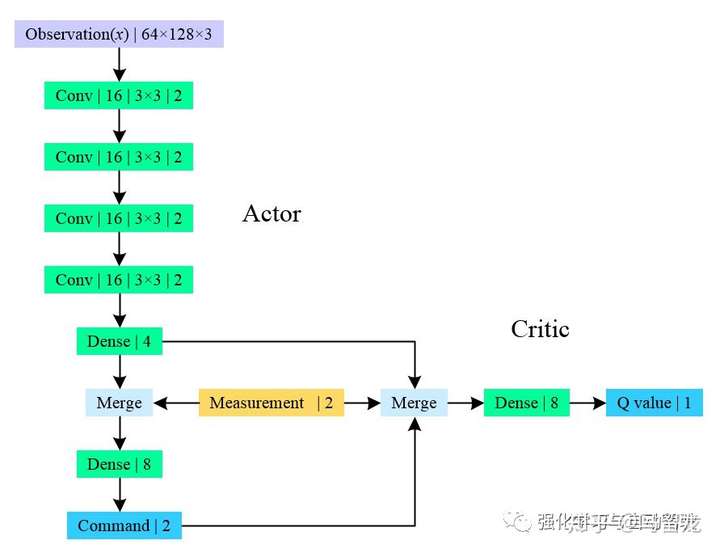
模型总共不到10k个参数,保证了高采样效率。在仿真环境中10个episodes的数据就可以训练得很好,真实环境中11个episodes就完成了250m道路的行驶,总共用时15~20分钟。并在不同天气下重复了这一过程以应对不同天气。其他细节:
- 训练模型用到的计算平台是NVIDIA Drive PX2,可满足实时性。
- 为了增加exploration,在optimal policy中增加了Ornstein-Uhlenbeck过程噪声。
- 想象学习(Dreaming about Driving)
人类拥有想象力,想象可以简单理解为过去记忆的重组,神经科学称之为constructive episode simulation。这种能力对于人类学习新技能有很大帮助,在这个过程中有一个关键机制是prediction model,人类在幼年时会从实际经验中学习一个内在simulator(prediction model)来预测、理解世界,然后我们的大脑会根据这个simulator来学习从接球到驾驶等各种技能。
Wayve也据此提出了相似的模型,该模型使用离线的真实环境数据去训练一个prediction model。模型的基础是18年提出的World Models,World Models将端到端的决策模型分为视觉部分、记忆部分以及控制器,三部分可单独训练,我们也尝试用该模型去解决第三等级的导航任务,相关工作发表后会开源。作者同时强调了temporal information对于prediction的重要性,如下图单凭这样一张静态图片我们都无法预测出汽车是在加速还是刹车,更不用说拟人的神经网络了。因此prediction model要能够处理时序信息,很自然地可以在其中引入递归神经网络(RNN)。

Wayve使用编码器来压缩图像,将压缩后得到的state vector以及当前的Steering & Speed作为prediction model的输入,输出预测Reward和下一时刻的state vector,这与World Models中的视觉部分、记忆部分相似。过程如下:
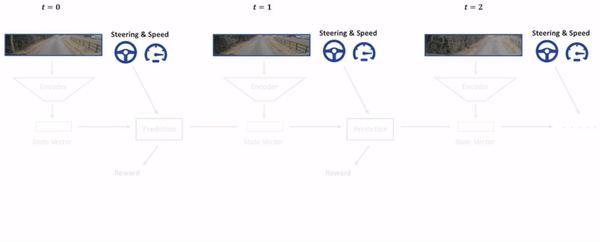
因此离线收集到的Observation和Steering & Speed序列数据就可以训练encoder和prediction model。其中,encoder仍然使用的是VAE,prediction model使用了Probabilistic Recurrent Neural Network。
训练好了encoder和prediction model就可以通过Imagination来学习策略了,这与World Models中的控制器训练相似。过程如下所示:

之前用于训练prediction model的数据是在晴天收集到的,通过Imagination学习得到的策略不仅可以在同一天气中运行稳定,更令人激动的是在雨天车辆依然可以很好的驾驶:

即在学习过程中,系统更多注意的是与驾驶策略相关的信息,而非雨水、雨刷等不相关的量,使得决策不被影响,该工作在强化学习广为诟病的泛化性能上取得了很好的效果,很有启发性。
后记:Wayve的这两项工作都很有意思,在他们之后的工作中会使得模型更加强大,之后的系列文章会继续在公号(强化学习与自动驾驶)发布。
感谢阅读,欢迎关注微信公众号:强化学习与自动驾驶