本文摘自:《逆流而上:阿里巴巴技术成长之路》
3.2 波谲云诡,数据库延迟
背景
某业务在生产环境遇到了一个诡异的数据库访问现象:应用通过数据库中间件TDDL访问MySQL数据库,偶尔会出现超长的访问延迟,导致整个远程服务接口调用超时。从调用链分析平台EagleEye(分布式调用的跟踪者)看到的图形是这个样子(如图3-9所示)。

从这张图上可以看出:
(1)访问多张表的延迟都超过500ms;
(2)同一笔调用,查询另一些表的延迟只有1ms;
(3)都是访问同一台数据库。
在什么情况下会出现这种现象呢?发现下列3种情况,问题完全难以捉摸:
(1)大约0.3%的服务调用出现这种超时,其他请求完全不受影响;
(2)几乎不受业务访问压力的影响,包括预发环境也能重现这种超时;
(3)所有应用服务器上都能重现。
问题分析
会不会是应用、中间件、网络、数据库上产生了资源等待?
答案是不会。因为所有业务请求都需要相同的资源,大家都在同一个资源池上排队。假设请求是相同的,排队是公平的——如果有人排队等了500ms才拿到资源,有人1ms就拿到了资源——那么,一定会有等待了100ms,200ms,300ms,400ms这样的请求,访问延迟应该体现平均分布。
但现象与预设显然不符。那什么场景下才会产生明显的延迟差距?有以下几种情况:
(1)锁等待
有几行数据被加锁,造成部分请求长时间等待锁。或者,出现非公平的锁等待,插队太多,请求被“饿死”。
(2)热点数据
部分业务ID返回的数据量很大,或者需要扫描的索引数据行数很多。
(3)IO抖动
高IO压力下,命中缓存的请求和需要访问磁盘的请求延迟(因为IO排队)差别会很大。
(4)未知问题
除以上外,也不能排除是应用、中间件、或者数据库的未知问题导致。
首先,锁等待和IO抖动的问题被排除了,因为发生问题的数据库请求都是SELECT语句,MySQL InnoDB引擎支持多版本并发控制(MVCC),普通SELECT查询是不加锁的。
此外,数据库压力很低,缓存命中率很高,可以排除是IO的原因(如图3-10所示)。 数据不均匀的可能性也被排除了。业务查询中有一部分是主键查询,符合条件的数据有且只有一条。并且,仔细筛查EagleEye平台提供的调用链记录发现:相同参数的远程服务调用,也会出现有时快、有时慢的现象。
最后,DBA在业务数据库监控上完全看不到慢查询。上文1、2、3三种情况导致的SQL执行时间大于1s都会记录在MySQL慢查询日志。从EagleEye平台可以看到最高延迟超过2s,但是MySQL数据库的慢查询日志却没有任何记录。
已知可能性都被排除了,所以只能通过日志分析寻找问题特征。
日志分析
从数据库中间件TDDL记录的统计日志tddl-stat.log发现:业务数据库使用了分库分表,一共包含8个分库,高延迟查询都来自其中的两个分库。
V1 201x-xx-xx 16:24:24:629 read statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_00_3306 times:1779 errors:0 qps:29 rt(avg/min/max):94/0/2164 ]
V1 201x-xx-xx 16:24:24:630 write statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_00_3306 times:6 errors:0 qps:1 rt(avg/min/max):0/0/1 ]
V1 201x-xx-xx 16:24:24:630 dataSource statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_00_3306 poolSize:30 active(now/max):3/9 pooling(now/max):10/13 create:0 destroy:0 errors:0 ]
V1 201x-xx-xx 16:24:24:630 read statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_01_3306 times:1647 errors:0 qps:27 rt(avg/min/max):69/0/2164 ]
V1 201x-xx-xx 16:24:24:630 write statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_01_3306 times:14 errors:0 qps:1 rt(avg/min/max):0/0/1 ]
V1 201x-xx-xx 16:24:24:630 dataSource statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_01_3306 poolSize:30 active(now/max):2/8 pooling(now/max):11/13 create:0 destroy:0 errors:0 ]
V1 201x-xx-xx 16:24:24:631 read statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_02_3307 times:1829 errors:0 qps:30 rt(avg/min/max):0/0/1 ]
V1 201x-xx-xx 16:24:24:631 write statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_02_3307 times:10 errors:0 qps:1 rt(avg/min/max):0/0/1 ]
V1 201x-xx-xx 16:24:24:631 dataSource statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_02_3307 poolSize:30 active(now/max):0/8 pooling(now/max):8/8 create:0 destroy:0 errors:0 ]
…
可以看出00和01库的查询延迟指标: rt(avg/min/max):94/0/2164 与下面的02库 rt(avg/min/max):0/0/1 完全不同,而且每个周期的统计日志重复该现象。
巧合的是,00/01库正巧位于同一个MySQL实例10.x.77.4:3306上,业务的其他分库则全部位于同一台物理机的其他MySQL实例(10.x.77.4:3307~3309)上。这说明问题更可能与这个数据库实例有关。因为分库分表后,数据库中间件TDDL处理不同分库没有区别,不会导致00/01库出现高延迟查询,而02-07库完全没有问题。
DBA检查了10.x.77.4上的4个MySQL实例,没有发现3306端口的实例配置有特殊差异。从数据库监控看,3306与其他实例的监控曲线也没有明显的差别。
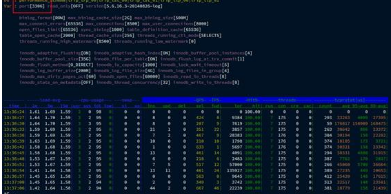
由于应用端统计到的数据库延迟很高,而数据库端看到的查询执行很快。怀疑的目标转移到了网络上。难道是网络问题?抓个包看看(如图3-11所示)。
抓包分析
tcpdump host 10.x.77.4 and port 3306 -s 0 -w dump.pcap
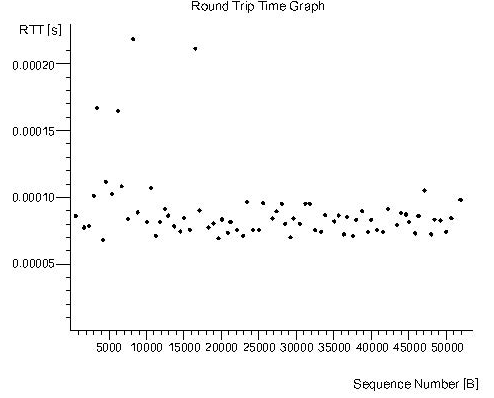
Wireshark提供的RTT(Round Trip Time)统计表明网络延迟很低(如图3-12所示)。
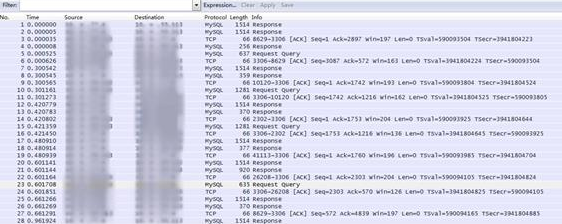
如图3-13所示,从抓包的确可以看出有一些MySQL请求的延迟很高(600ms):
如图3-14所示,大多数请求的延迟比较正常(3ms)。
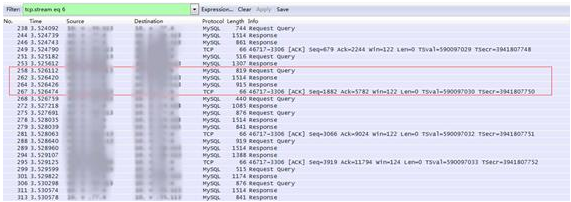
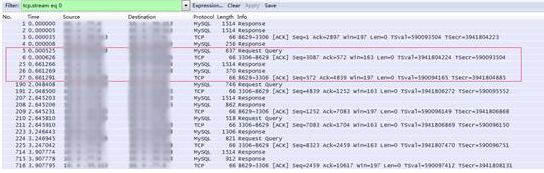
但是发现一个特殊现象:同一条TCP连接的请求,要么都慢(500ms以上),要么都快(5ms以下),如图3-15所示。
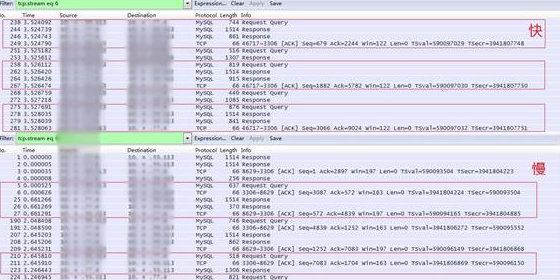
这个状况有点复杂,很少有因素影响单个TCP连接的处理效率。考虑了以下几个因素:
网卡硬件问题?
TCP连接分配的网卡中断处理不均衡?
负责处理请求的MySQL线程被绑定到繁忙的CPU上?
结果都不是。
抓包后继续监控TDDL统计日志,发现高延迟查询的现象从16:42起完全消失了,现在00/01库的延迟统计数据与其他分库一样稳定:
V1 201x-xx-xx 17:20:24:629 read statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_00_3306 times:1826 errors:0 qps:30 rt(avg/min/max):0/0/6 ]
V1 201x-xx-xx 17:20:24:629 write statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_00_3306 times:24 errors:0 qps:1 rt(avg/min/max):0/0/1 ]
V1 201x-xx-xx 17:20:24:630 dataSource statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_00_3306 poolSize:30 active(now/max):0/7 pooling(now/max):11/11 create:0 destroy:0 errors:0 ]
V1 201x-xx-xx 17:20:24:630 read statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_01_3306 times:2393 errors:0 qps:39 rt(avg/min/max):0/0/3 ]
V1 201x-xx-xx 17:20:24:630 write statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_01_3306 times:13 errors:0 qps:1 rt(avg/min/max):0/0/3 ]
V1 201x-xx-xx 17:20:24:630 dataSource statistics
[ appName:TRIP_TTP8_APP dsKey:g1-myb077004_et2_trip_ttp_01_3306 poolSize:30 active(now/max):0/7 pooling(now/max):13/13 create:0 destroy:0 errors:0 ]
…..
询问业务方,得知服务调用超时的问题也消失了。再询问DBA, DBA的确在16:42的时候操作了生产数据库:杀掉(kill)了10.x.77.4:3306上的多余DRC Binlog采集线程。
什么是DRC ?
DRC是一个阿里集团内部采集数据库增量数据的服务。它使用MySQL主备复制协议,在数据库启动一个长时间运行的Binlog采集线程,持续抓取新生成的MySQL Binlog日志传输到另一端的DRC服务节点。
为什么杀掉DRC Binlog采集线程会改变业务的访问延迟?之前在MySQL上从没有遇到过。因为DRC使用MySQL内置的主备复制协议,对数据库的影响理论上跟一台MySQL备库没有区别。 尽管DRC会长期占用一个MySQL线程,但是普通MySQL是一个线程服务一个连接的调度方式,除了IO,锁和CPU切换,不同连接上的请求不会相互影响。
咨询DBA才知道:业务的MySQL最近从5.5升级到5.6,新增了线程池功能,问题的核心出在线程池。
MySQL线程池
MySQL线程池是个高大上的功能。拥有线程池的MySQL Percona分支以及官方MySQL企业版声称可以“提升MySQL扩展性60倍”。它的优势是能让MySQL用较少的线程支持更多的数据库连接与网络并发。因为线程数太多会在锁和IO上产生更多的竞争,使得更多的CPU资源消耗在上下文切换、自旋(spin)和内核调度上。
MySQL的线程池相比类似组件做了更多的优化。其中一个优化是对线程资源进行了分组,每个分组只有少量(2~3个)线程。这样每个组的资源相互隔离,防止慢查询耗尽全部线程资源,导致MySQL无法响应业务请求。
在分组模式下,如果有新的TCP连接上MySQL,新连接会以散列的方式固定分配到一个分组,由这个分组内的线程负责响应连接上的请求。当处理结束,响应请求的线程释放连接,接着去处理同一个分组内其他TCP连接上的请求。
但是上面已经提过,DRC发起的连接与普通连接不一样。它请求的Binlog Dump任务始终不会结束,这样执行DRC请求的线程就会一直无法释放。而MySQL分组内的线程实在太少了。如果正好有一个分组分配到2个以上的DRC连接,该分组内就没有空闲线程来响应其他请求了。因此,被固定分配到这个分组的TCP连接得不到线程处理,表现在应用端就是高延迟。
注:这里表现出高延迟而不是超时,原因是MySQL线程池有另外一个参数thread_pool_stall_limit避免无限期等待。请求如果在分组内等待超过thread_pool_stall_limit时间没有被处理,则会退回传统模式,创建MySQL线程来处理请求。这个参数的默认值正好是500ms。
顺便由于请求是堆积在TCP缓冲区中没有被处理,MySQL端是无法记录到这类请求的等待时间的。这样,MySQL的慢查询日志就不会有记录。
知道原因后,解决问题就简单了:
临时解决方案是尽量减少单个MySQL实例上的DRC连接的数目。
最终解决方案是优化MySQL线程池,让Binlog Dump这类特殊请求归属到独立的线程池处理,或者绕过线程池,回归到一个线程服务一个连接的模式。
小结
本文这个案例的分析和排查过程比较有意思。其实一开始的分析已经接近了问题的本质:资源池的均衡问题——如果所有请求都在同一组资源上排队等待,那么访问延迟一定是连续分布的。MySQL的线程池分组功能实际上拆分了资源池,使得不同的请求分别在不同的资源池上排队。当这些池中的资源数量不同,那么就一定会有请求更容易得到资源,有些请求拿不到资源,出现类似的延迟分布。
另外,从排查过程可以发现,EagleEye这样的调用链分析平台对判断分布式系统问题非常关键,利用平台提供的调用链数据,可以在初期迅速排除掉一系列可能性,将问题聚焦。在线上问题处理中,排查人员往往面临快速定位原因,恢复系统的压力。这时,聚焦问题就是最大的帮助。