论文链接:https://arxiv.org/abs/2209.03793
写在前面
传统卷积受限于固定的几何结构,无法高效捕获空间与通道的远程依赖。本文提出的方法不仅拥有可调整的动态感受野,而且突出了像素之间的负关系。另外本文针对传统生成对抗网络,设计了一种新的生成策略,进一步稳定和加快了训练过程。
生成对抗网络(GAN)预热
本文方法致力于从高维数据分布中生成现实多样的样本,在正式步入主题之前,对GAN原理作简要介绍,已熟悉的读者可跳过这一部分。
GAN包括生成器与判别器,以图片为例。生成器的任务就是生成图片,其输入可以是随机噪声。判别器的任务就是用以判断生成的图片是否真实。
整体的训练流程就是让生成器输出“真实”图片,让判别器拥有良好的鉴别能力。如下图所示:
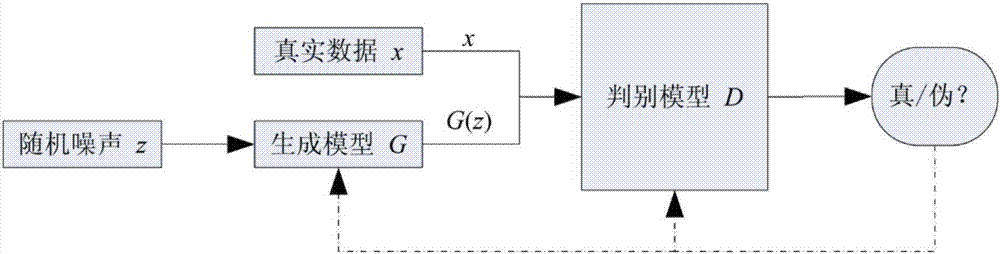
生成器与判别器的训练形成了一个不断博弈的过程,最终当生成器接近收敛时,生成图片数据拥有与真实图片数据一致的分布模式。但事实上,生成器与判别器的设计非常重要,如设计不当,则易导致生成器发散。
GAN常见的应用场景有人脸生成、物品生成、图像修复、数据增强等等。本文即对生成器的设计进行研究。
传统方法的痛点
自14年GAN被提出以来,许多针对生成器设计的研究涌现,然而这些方法大多建立于传统卷积的基础上。
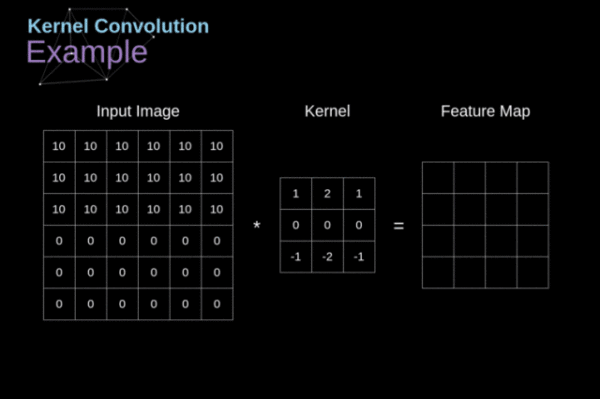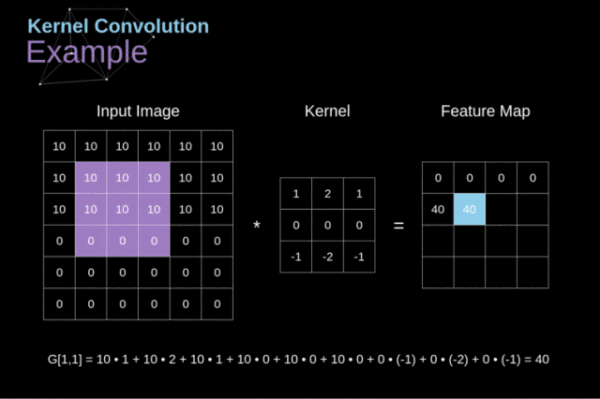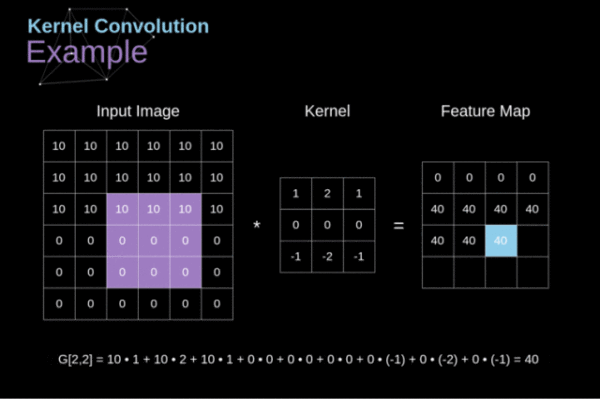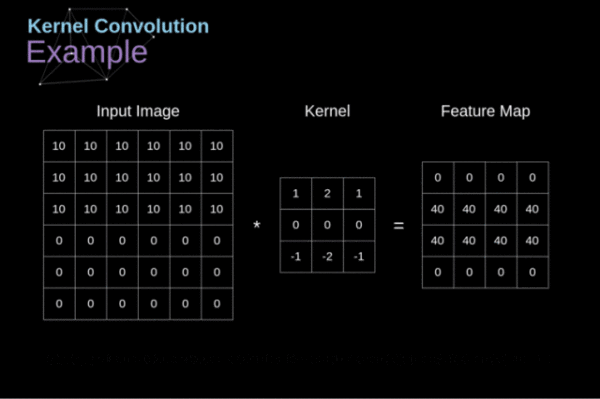
卷积算子受限于固定的几何结构(如图2),难以高效捕获远程依赖。最直接的解决方案就是增加卷积层的深度,但增加的复杂度对资源受限设备来说是难以接受的。除此之外,可变形卷积通过学习偏移量来改变传统几何结构,进而捕获远程依赖,但其卷积算子的大小是固定的,即单次计算的像素数量是受限的。
另外,传统的生成器为实现更高的性能,常常是高度复杂的,这为训练或推理带来一定压力。因此除了对结构设计进行调整外,如何通过其他手段来减轻训练负担也是需要研究的方向。
一个捕获远程依赖的神器
相信很多读者看到标题就想到是什么了,这个神器近年来多次与“卷积”、“感受野”这些关键字一起出现。自Transformer成功应用以来,许多卷积与自注意结合的工作出现。
得益于全局多头并行机制,自注意可以很轻松的捕获对象的远程依赖,相比卷积的不断加深层数,无论复杂度还是模型表现都得到进一步优化。

但众所周知,自注意也不算完美。在本文中,作者观察到由于自注意中softmax函数的存在,使得相关性矩阵中几乎所有值都大于0。也就是说,在传统的自注意计算中,所有像素之间只存在积极影响,即正关系,而没有负面影响。
可能有读者会认为,自注意中,softmax后的注意矩阵中有的权重高,有的权重低,不就代表着增强或抑制嘛。这种想法当然没错,但权重高低的直接体现均为正值的大小,作者这里考虑的是更强烈的“负面影响”,即突出某些负关系。而且在图像生成中,某些负面关系可以作为正则化来稳定训练过程并防止模式崩溃。
现将上述三个痛点整理并简述如下:
- 卷积算子的几何结构受限,难以高效捕获远程依赖。
- 以往生成器高度复杂,为训练和推理带来负担。
- 自注意计算中各像素之间仅产生积极影响,忽略了负面影响。
综上,本文提出了一种拥有可调整的动态感受野方法,同时突出了像素之间的负关系,并通过设计新的生成策略,进一步稳定和加快训练过程。
本文方法详解
首先给出本文方法的整体架构,如下所示:
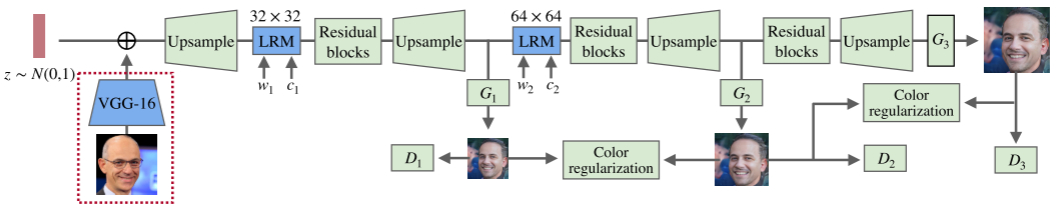
给定从高斯分布N(0, 1)中随机采样的输入噪声z,将经过上图所示的流程生成目标图像。图中G表示生成器,D表示判别器。不难看出架构中存在多个G和D,这样的多阶段设计可以提升模型性能。
在GAN的预热部分有提及,“生成器与判别器的设计非常重要,如设计不当,则易导致生成器发散”。事实上,作者发现,当模型的参数较少时,这种情况极易出现。
而多阶段架构的设计让生成过程“循序渐进”,随机的噪声输入先生成低分辨率结果,再通过顺序结构逐步得到目标结果。在这个过程中,中间的低分辨不仅存在于真实图相交的概率,同时也可作为一种约束来限制后续生成过程中产生的随机性。
约束是什么? 如图,作者采用Color regularization来实现这一约束。为了防止后续过程产生的颜色不一致性,对低分辨输出采用颜色一致性正则化方法。
举个不太恰当的例子,我们从上学起就开始接触数学,从最开始小学的加减乘除,到高考时的积分微分。如果我们刚入学时就直接从高考数学学起,那这个过程无疑是十分痛苦的,而如果有了小学、初中的基础知识,那么高考数学也相对容易许多。
下面将对本文方法的核心模块LONG-RANGE MODULE(LRM)讲解。
LRM的设计初衷即是解决上述GAN的痛点问题,建立于卷积与自注意计算的基础之上,其中包括空间方向与通道方向。
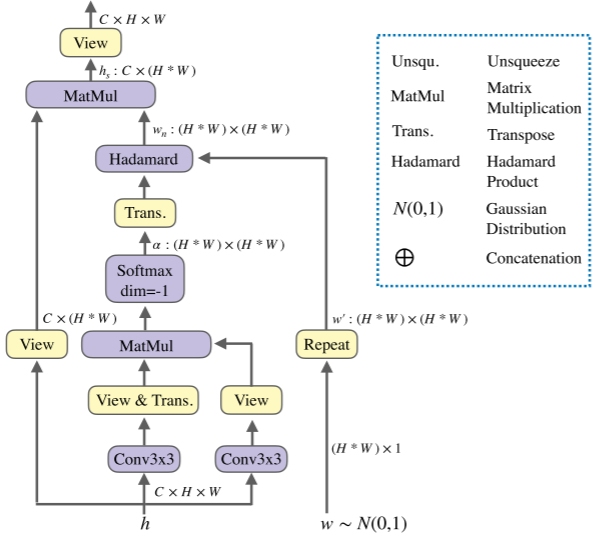
图5为空间方向的LRM示意图,输入分别为特征图w∈RC×H×W以及从高斯分布中得出的可学习权重w∈R(H∗W)×1。
同传统自注意计算过程一致,输入特征h经过线性变换与形状转换得到Q、K、V,注意这里作者仅对Q、K使用3×3的卷积,而V则直接进行形状转换。紧接着Q与转置后的K相乘来计算相关度,经softmax函数归一化后得到注意矩阵α。
这与以往的线性变换有所不同,在传统的vision transformers中,线性变换通过密集的linear实现,且V也要经过线性变换。但后续有工作证明,即使不对V进行变换,直接copy原输入也可以达到较好的效果。这样不仅仅省下了linear的计算开销,也相对保证了性能。
与此同时,另一个输入w∈R(H∗W)×1经repeat操作得到w′∈R(H∗W)×(H∗W),接着将w′与α的转置相乘得到最终的空间关系感知权重wn,此时只需将wn作用于V,即可得到一个包含了远程依赖的特征输出集。
为什么得到了注意矩阵α还要进一步得到空间关系感知权重wn?有这个问题的读者要细心啦~前面提到LRM用以解决传统方法的几个痛点问题,其中就包括传统的自注意中,各像素之间仅产生积极影响,忽略了负面影响。而由可w′学习权重变换而来,当w′与α的转置相乘,即将可学习权重作用于原注意矩阵,那么各像素之间产生的影响就会被重新缩放,从而改善原注意矩阵中仅存在积极关系的问题。
通道方向上的LRM如下图所示:
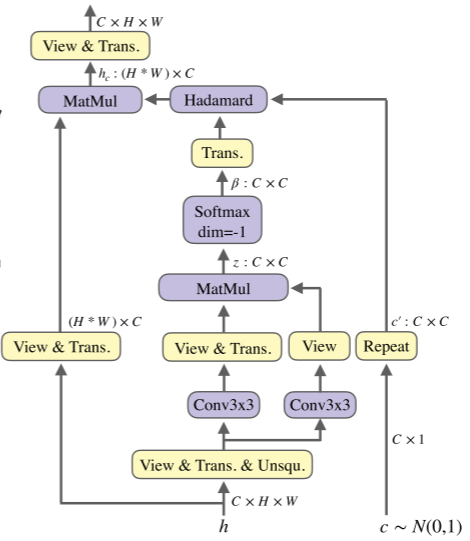
与前者不同的是,这里的输入可学习权重c的尺寸为C×1,且中间注意矩阵尺寸为C×C,其他过程与空间方向的保持一致。
最后,为了加快训练过程,作者将元数据添加到模型中,旨在向生成器提供有关目标图像的基本信息,即“让生成器提前知道要合成什么样的对象”。其流程示意如图4最左侧所示。
作者使用预训练好的VGG-16来对元数据进行特征提取,并将VGG-16的深层输出特征添加到GAN的噪声输入。
当然在添加之前,为了简化空间信息,滤去不必要的细节特征,如颜色、形状、姿态等,作者将特征集沿通道方向平均池化,这样既保留了元数据的基本信息,又对生成模型起到较好的帮助作用。
实验结果展示
数据集:ImageNet、FFHQ、CUB bird
对比方法:PGGAN、SAGAN(由于StyleGAN和StyleGAN 2都基于PGGAN,且具有更复杂的结构,这与本文的轻量级目标相悖,因此作者并未与其对比)
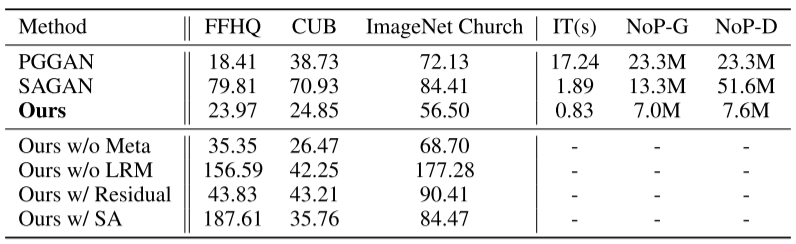
评价指标为FID,越低越好。IT表示生成100个新结果的推理时间最右侧两列代表生成器(NoP-G)和鉴别器(NoP-D)中的参数量。
“Ours w/o Meta” 表示没有提供元数据。
“Ours w/o LRM” 表示没有使用LRM。
“Ours w/ Residual” 表示使用残差块替换LRM模块。
“Ours w/ SA” 表示使用传统自注意而不是LRM。

思考与总结
本文提出了一种轻量级的生成对抗模型,通过与可学习权重相乘得到对注意矩阵的重缩放,从而解决了传统自注意中仅存在正关系的局限。通过引入自注意来打破卷积算子固定结构带来的影响,简单且直接的捕获了对图像生成必不可少的远程依赖。另外为了加快训练速度,将元数据通过预训练模型提取主要特征后添加到GAN的噪声输入中,使生成模型轻松知道它的目标是什么。最后通过实验与两种对比方法获得了竞争性的结果,从效果展示中不难看出本文方法的潜力。
感谢大家抽出宝贵的阅读时间,希望这篇文章能给大家提供一定帮助~