你拿到LLaMA的代码了吗?觉得这个训练方法如何?
基于Meta模型打造的轻量版ChatGPT,这就来啦?
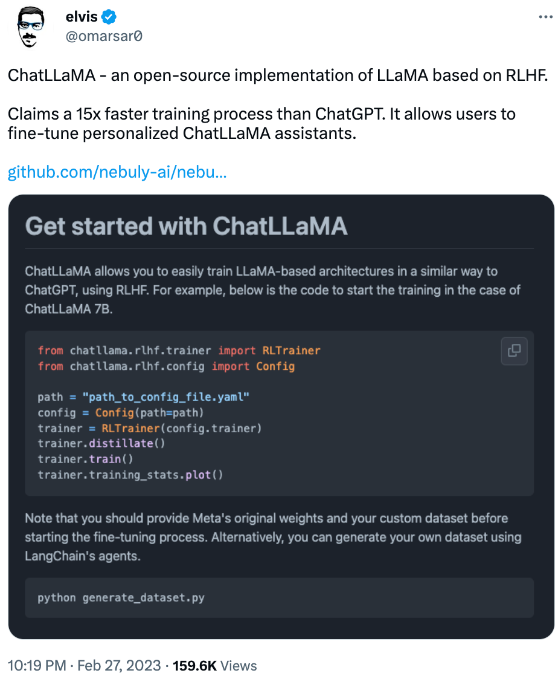
Meta宣布推出LLaMA才三天,业界就出现了把它打造成ChatGPT的开源训练方法,号称比ChatGPT训练速度最高快15倍。
LLaMA是Meta推出的超快超小型GPT-3,参数量只有后者的10%,只需要单张GPU就能运行。
把它变成ChatGPT的方法名叫ChatLLaMA,基于RLHF(基于人类反馈的强化学习)进行训练,在网上很快掀起了一阵热度。
所以,Meta的开源版ChatGPT真的要来了?
先等等,事情倒也没那么简单。
把LLaMA训练成ChatGPT的“开源方法”
点进ChatLLaMA项目主页来看,会发现它实际上集成了四个部分——
DeepSpeed、RLHF方法、LLaMA和基于LangChain agent生成的数据集。
其中,DeepSpeed是一个开源深度学习训练优化库,包含名叫Zero的现存优化技术,用于提升大模型训练能力,具体指帮模型提升训练速度、降低成本、提升模型可用性等。
RLHF则会采用奖励模型来对预训练模型进行微调。奖励模型即先用多个模型生成问题问答,再依靠人工对问答进行排序,让它学会打分;随后,基于奖励学习给模型生成的回答进行打分,通过强化学习的方式增强模型能力。
LangChain是一个大语言模型应用开发库,希望将各种大语言模型整合起来,结合其他知识来源或计算能力创建一个实用的应用程序。LangChain agent则会像思维链一样放出GPT-3思考的全过程,将操作记录下来。
这时候你会发现,最关键的依旧是LLaMA的模型权重。它从哪里来?
嘿嘿,自己去找Meta申请吧,ChatLLaMA并不提供。(虽然Meta声称开源LLaMA,但依旧需要申请)
所以本质上来说,ChatLLaMA并不是一个开源ChatGPT项目,而只是一种基于LLaMA的训练方法,其库内集成的几个项目原本也都是开源的。
实际上,ChatLLaMA也并非由Meta打造,而是来自一个叫做Nebuly AI的初创AI企业。
Nebuly AI做了一个叫做Nebullvm的开源库,里面集成了一系列即插即用的优化模块,用于提升AI系统性能。
例如这是Nebullvm目前包含的一些模块,包括基于DeepMind开源的AlphaTensor算法打造的OpenAlphaTensor、自动感知硬件并对其进行加速的优化模块……

ChatLLaMA也在这一系列模块中,但要注意的是它的开源license也是不可商用的。
所以“国产自研ChatGPT”想要直接拿去用,可能还没那么简单(doge)。
看完这个项目后,有网友表示,要是有人真搞到LLaMA的模型权重(代码)就好了……
但也有网友指出,“比ChatGPT训练方法快15倍”这种说法是一个纯纯的误导:
所谓的快15倍只是因为LLaMA模型本身很小,甚至能在单个GPU上运行,但应该不是因为这个项目所做的任何事情吧?
这位网友还推荐了一个比库中效果更好的RLHF训练方法,名叫trlx,训练速度要比通常的RLHF方法快上3~4倍:
你拿到LLaMA的代码了吗?觉得这个训练方法如何?
ChatLLaMA地址:https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
参考链接:https://twitter.com/omarsar0/status/1630211059876339713